빈도분포와 그래프
box plot

가장 중요하다
Q1 원점수. 25백분위 수. 칸막이
Q3 75백분위수.
Q2 중앙치
자료 분포에 대한 정보를 간략하게 그린 것이다.
Q1~Q2 사이 전체 25% / Q2~Q3 전체 25% 구간
이걸 보고 원래 그래프 모양을 유추할 수 있어야 한다
그러니까 그래프를 중심으로 좌측에 중심점이 있으면 좌측에 빈도가 높은 것이다
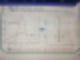
확률밀도함수랑 박스플랏이다
정규분포는 중앙치가 평균이다. (중앙치 = 평)
2개의 분포에 대해서 박스플랏을 그렸을 때, 중앙값은 똑같다
좌우대칭이니까 Q1~Q2 Q2~Q3 간격도 똑같다. 다만 2개 박스플랏 차이점은 넓고 좁다
1000개 랜덤샘플한 다음에 그린 그림
좌우대칭했지만 이상치값(특정 지정된 그룹에 분류되지 못하는 값)이 다르다 – 왜? 랜덤값이기 때문에
그러니까 표준편차가 작으면 작을수록 솟아올라와 있고, 표준편차가 크면, 평평한 모양이 된다
표준편차가 적을수록 평균에 모여있다고 볼 수 있다.
중심 경향, 분산& 상관
백분위수. 점수를 정리할 때 순서대로 정리하는 것이 기본적인 접근방식이다.
서열적 위치가 정해진다. 어떤 숫자가 백등분 했을 때, 위치를 계산해서 얻은 점수가 백분위라고 한다.
반대로 백분위가 가지는 점수가 무엇인가? 이를 백분위수 라고 한다
이 2가지가 가장 중요하다
백분위수 중에서 중요한 게 중간점수 = 중앙치 = 중위수 = median
백분위와 백분위수
백분위와 백분위수를 구할 때 (이산점수)를 다루기 때문에 관심 가지는 선형보간법이 필요하다
그럴듯한 가정을 해서 구하는 것이기 때문에 정확히 구하긴 힘들다

중심경향치: 한 집단의 점수분포를 하나의 대표 값으로 요약해주는 대표치
대표적으로 산술평균, 중앙치, 최빈치 등이 있다

점수들의 합을 구하면 된다. 10명의 자료를 정리한 것이다.
점수와 빈도가 주어졌을 때는 전체 고유의 점수와 빈도를 곱해서 부분합을 구해서 전체 합을 구한다
정의에 충실하게 산술평균이 구해진다
분모. 빈도의 전체합. 상수. 이를 분자에 넣어도 값이 똑같다
Fi/n => 상대빈도. 상대빈도를 w라고 놓는다. 평균은 모든 발생 가능한 고유값의 합으로 정의할 수 있다
각 값이 있는데 이 값의 가중치가 있는 것이다. 어떤 것이 더 무겁다 라고 생각하면 된다. 더 무거운 쪽에 더 많은 가중치가 주어진다는 것이다. 가중치가 높은 쪽으로 쏠리기 마련히다. 평균은 반드시 최대값 최소값 사이에 존재해야 한다.
어떤 값이 1이다는 말은 다른 값이 존재하지 않는다는 말이다. 그렇지 않으면 가중치가 높은 것으로 쏠리기 마련이다
1반의 점수 2반의 점수 3반의 점수
전체 평균은 얼마지? 1반의 평균이 얼마지?
알아보고 숫자를 넣으면 전체 반의 평균이 된다
아예 각 반의 평균점수를 출발점으로 본다
초보적인 원래 식으로 맞춰보면, 전체 사례수를 곱하면 평균을 구할 수가 있다
첫째 집단의 가중치를 알고 이를 곱하고, 2번째 집단의 가중치를 곱하면 숫자를 알 수 있다
두 반의 평균값의 사이에 얻어진다.

가장 흔히 사용되는 것이 선형변환
변수 x값이 주어질 때, 새로운 변수 y를 얻는 것이다. A 기울기 b 절편
선형변환하게 되면, 절편이 b고, a가 기울기이다

평균 x에 관한 편차점수의 제곱의 합은 다른 어떤 기준 값 c에 관한 편차 점수의 제곱의 합보다 작음
어떤 c값은 평균x + d로 표현된다
그러면, 아래와 같은 식을 만들 수 있다
여기에서 가장 중요한 것은 C= X+D 라느 가정이다
이렇게 나타내지 않으면 이후의 과정이 도출되지 않는다
중앙치 구하기 중에서 이게 급간으로 묶은 빈도분포표가 주어졌을 때 구하기가 좀 어렵다
최빈치
가장 빈번한 값
빈도가 반드시 많다고 해서 최빈치가 아니다. 빈도를 말하는 것이 아니다
주의하지 않으면 실수한다
빈도랑 점수를 혼동하지 않기를 바란다
만약 빈도가 높은 두 수가 인접해 있다면, 두 값의 평균을 활용
아니면, 최빈치가 2개가 나타날 수 있다(양봉분)
최빈치는 연속변수면 곤란해진다. 연속변수에 대해 확률 모형에 대해 배울 것이지만, 정규분포 비슷한 것이 있다. 분포를 매끄럽다는 것이는 것은 밀도를 기록한 곡선이다.
일어날 가능성을 갖는 것이다. 실수는 무한하다. 무한한 값의 빈도를 구할 수 없다.
봉우리가 1개다. mode라고 불린다. 8이 mode이다. 최빈치를 찾을 경우에도 x축에 높은 봉우리에 찾아야 한다.
최빈치를 찾을 때, 그 값을 찾으라는 것이다.
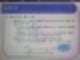
많은 빈도가 2개일 때? 그때 우리는 진짜 최빈치가 무엇인가? 의사결정이 필요하다
3.5 라고 대답할 수가 있는데 3.5라는 값은 존재하지 않는 값일 수 있다.
3.5가 발생하지 않을 때? 이산숫자는 그렇다.
예를 들어서 나이를 계산할 때? 25.5세가 맞는가?
그리고 모든 값이 다 같을 때?? 공동 1등일 때. 최빈치가 존재하지 않는다고 말할 수 있다.
평균, 중앙치, 최빈치 특징 비교
만약에 극단으로 치닫는 값을 갖고 있는 데이터라고 하면 그땐 평균이 어울리지 않을 수 있다
그럴땐 평균을 쓰는 것보다 대표치로 쓰는 것이 부적절할 수 있다

통상 정규분포를 적용해서 많이 푼다. 이론적인 분포이다. 그리고 이 중에서 알맞다고 하는 것을 갖다 쓰는 것이다.
실제로 현실에선 잘 맞지 않는다. 통계학자들이 개발한 것이다.
내가 생각(갖고 있는)하는 자료분포랑 같다고 가정한다
내 자료는 정규분포를 띈다고 가정을 한다.
그러면 평균과 표준편차만 알면, 그래프를 구현할 수 있다.
우리는 실제 이론을 공부한다.
중앙치 최빈치 평균의 관계가 중요하다
정규분포는 전체 합이 1이라고 가정한다.
빈도를 굉장히 밀도를 빈도를 누적시켰을 때 50%가 되었을 때 평균이 된다. 즉 중앙치가 평균이 된다. 최빈치가 평균이 또 된다.
부적편포. M0 최빈치가 가장 오른쪽에 있다.평균은 가장 낮은 지점에 있다. 왜? 평균은 가중합이라고 했는데, 꼬리가 굉장히 길다. 밀도가 낮음에도 불구하고 꼬리 쪽에 점수가 존재하다보니까 평균이 낮은 지점으로 향한다. Mdn이 분점이다.
정적편포. 높은 값대로 쏠리는 것이다.